TTS Frontend for Arabic
First, I'll go through the differences between conventional and end-to-end TTS systems.
A conventional TTS system has
- A front-end-text-analyzer. Analyzes text and converts it to features.
- A backend speech synthesizer. Converts features to audio.
The front end consists of
- Text normalizers. They tokenize phrases, and convert numbers to words.
- A text-to-phoneme converter. It transforms normalized text to phonemes. Phonemes are symbolic representations of how the text is pronounced.
For an end to end speech synthesis system, the front end is limited to only text normalization, diacritisation, and phonetization.
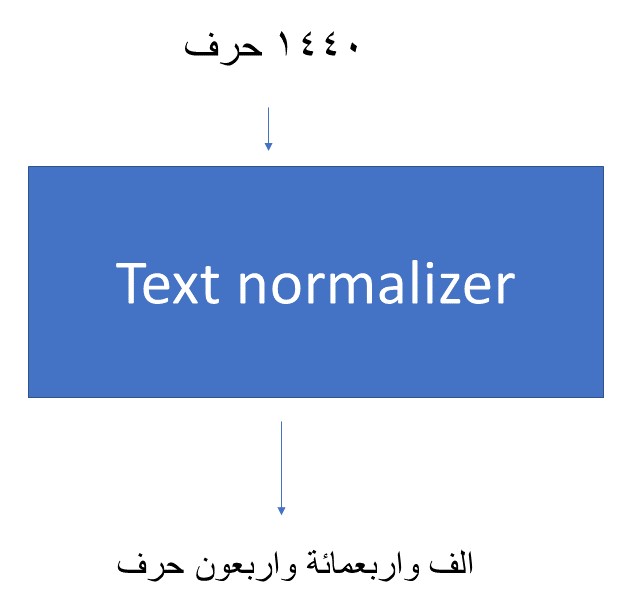
Text normalization
Text normalization is the first stage of processing done on the inputted text. Its job is to convert numbers, abbreviations and currency symbols to regular words.
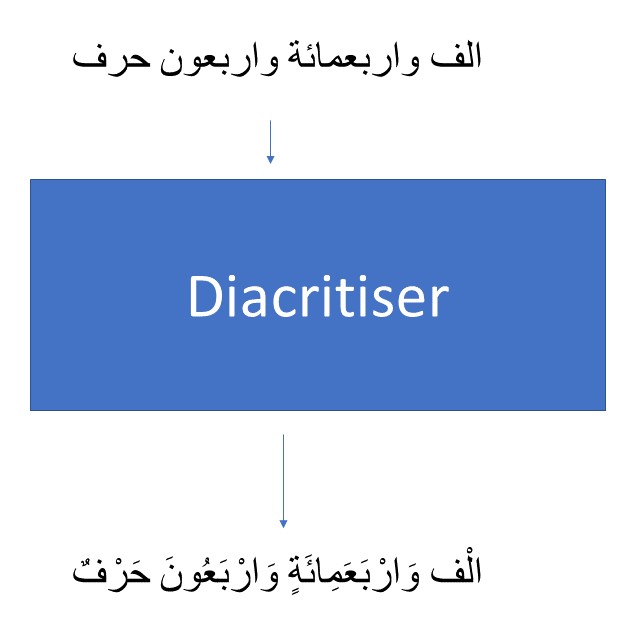
Diacritisation
The second stage of speech synthesis for the Arabic language is diacritisation. The Arabic language has twenty-eight consonants, three short vowels, and three long vowels. Long vowels are phonetically similar to short vowels except that they have a longer duration. Short vowels are generally not considered within the word structure in Arabic orthography. Arabic text could be diacritised or undiacritised. Undiacritised text includes only consonants and long vowels. Diacritised text includes consonants, long vowels, short vowels, and double consonants. The figure below shows the difference in orthography between diacritised text and undiacritised text.
Most of the mainstream Arabic text is written without diacritics since readers usually pronounce words correctly as they could assume the appropriate diacritics based on grammar, gender, context, etc. Diacritics are crucial for appropriate pronunciation of a word. Diacriticised Arabic orthography is close to phonemic representation. As mentioned before, diacritics are dependent on grammar, gender, context, and other factors. For a speech synthesizer to work appropriately diacritics are needed so that it could know how to pronounce words and here comes the role of the diacritiser.
Picked Diacritiser
I excluded Harakat, Madamira, Farasa, and Camel Parser. They were either not open source or hard to integrate with. Mishkal and Shakkala were popular and open-source. Mishkal is rule-based. Shakkala is statistically based. The later was regarded as a better option by the open source community.
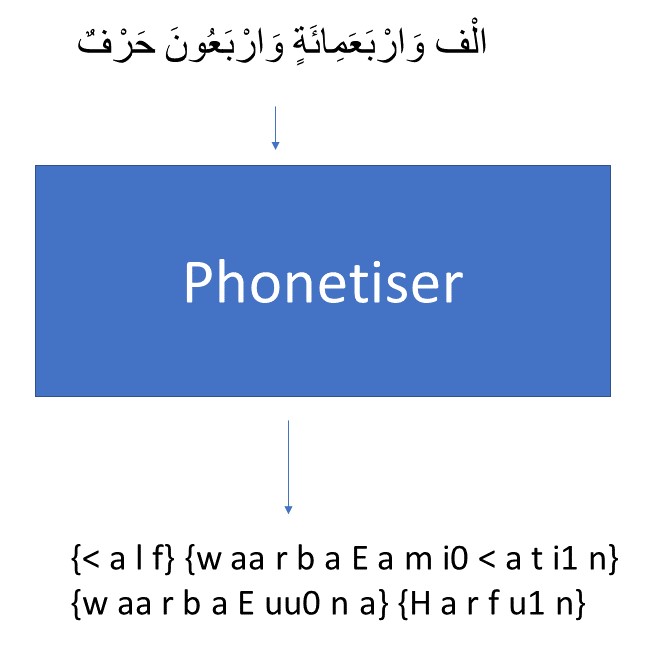
Phonetisation
Phonetization is the process of converting graphemes into phonemes which are direct representatives of audio sounds. In non-phonetic languages like English, orthography characters do not always map directly to phonemes. For example, the word "awesome" is converted to {AO1 S AH0 M}. Therefore, to have a phonetic representation for a word like "awesome" in English, phonetization is done manually. Also, the English language contains heteronyms, which are words with the same letters but are pronounced differently based on context. For example, the word "desert" have different pronunciations based on the context.
This is not the case in the Arabic language which is highly phonetic. For diacritised Arabic, a rule-based system could be used for phonetization. The best available graphemes-to-phonemes converter is Arabic Phonetiser. Arabic Pronounce is a wrapper for "Arabic Phonetiser" that allows it to be used as a service.
Open Source Arabic End to End TTS
Check the repo for Arabic Tacotron TTS here. Check also the samples for synthesized speech with only 2.41 hours of training data here